Building Blocks#
Here we explain the components of Ivy which are fundamental to its usage as a code converter.
Backend Functional APIs ✅#
The first important point to make is that, Ivy does not implement its own C++ or CUDA backend.
Instead, Ivy wraps the functional APIs of existing frameworks, bringing them into syntactic and semantic alignment.
Let’s take the function ivy.stack() as an example.
There are separate backend modules for JAX, TensorFlow, PyTorch, and NumPy, and so we implement the stack method once for each backend, each in separate backend files like so:
# ivy/functional/backends/jax/manipulation.py:
def stack(
arrays: Union[Tuple[JaxArray], List[JaxArray]],
/,
*,
axis: int = 0,
out: Optional[JaxArray] = None,
) -> JaxArray:
return jnp.stack(arrays, axis=axis)
# ivy/functional/backends/numpy/manipulation.py:
def stack(
arrays: Union[Tuple[np.ndarray], List[np.ndarray]],
/,
*,
axis: int = 0,
out: Optional[np.ndarray] = None,
) -> np.ndarray:
return np.stack(arrays, axis, out=out)
stack.support_native_out = True
# ivy/functional/backends/tensorflow/manipulation.py:
def stack(
arrays: Union[Tuple[tf.Tensor], List[tf.Tensor]],
/,
*,
axis: int = 0,
out: Optional[Union[tf.Tensor, tf.Variable]] = None,
) -> Union[tf.Tensor, tf.Variable]:
return tf.experimental.numpy.stack(arrays, axis)
# ivy/functional/backends/torch/manipulation.py:
def stack(
arrays: Union[Tuple[torch.Tensor], List[torch.Tensor]],
/,
*,
axis: int = 0,
out: Optional[torch.Tensor] = None,
) -> torch.Tensor:
return torch.stack(arrays, axis, out=out)
stack.support_native_out = True
There were no changes required for this function, however NumPy and PyTorch both had to be marked as supporting the out argument natively.
For more complicated functions, we need to do more than simply wrap and maybe change the name.
For functions with differing behavior then we must modify the function to fit the unified in-out behavior of Ivy’s API.
For example, the APIs of JAX, PyTorch, and NumPy all have a logspace method, but TensorFlow does not at the time of writing.
Therefore, we need to construct it using a composition of existing TensorFlow ops like so:
# ivy/functional/backends/tensorflow/creation.py:
def logspace(
start: Union[tf.Tensor, tf.Variable, int],
stop: Union[tf.Tensor, tf.Variable, int],
num: int,
base: float = 10.0,
axis: Optional[int] = None,
*,
dtype: tf.DType,
device: str,
) -> Union[tf.Tensor, tf.Variable]:
power_seq = ivy.linspace(start, stop, num, axis, dtype=dtype, device=device)
return base**power_seq
Ivy Functional API ✅#
Calling the different backend files explicitly would work okay, but it would mean we need to import ivy.functional.backends.torch as ivy to use a PyTorch backend or import ivy.functional.backends.tensorflow as ivy to use a TensorFlow backend.
Instead, we allow these backends to be bound to the single shared namespace ivy.
The backend can then be changed by calling ivy.set_backend('torch') for example.
ivy.functional.ivy is the submodule where all the doc strings and argument typing reside for the functional Ivy API.
For example, the function prod() is shown below:
# ivy/functional/ivy/elementwise.py:
@to_native_arrays_and_back
@handle_out_argument
@handle_nestable
def prod(
x: Union[ivy.Array, ivy.NativeArray],
*,
axis: Optional[Union[int, Sequence[int]]] = None,
dtype: Optional[Union[ivy.Dtype, ivy.NativeDtype]] = None,
keepdims: bool = False,
out: Optional[ivy.Array] = None,
) -> ivy.Array:
"""Calculate the product of input array x elements.
x
input array. Should have a numeric data type.
axis
axis or axes along which products must be computed. By default, the product must
be computed over the entire array. If a tuple of integers, products must be
computed over multiple axes. Default: ``None``.
keepdims
bool, if True, the reduced axes (dimensions) must be included in the result as
singleton dimensions, and, accordingly, the result must be compatible with the
input array (see Broadcasting). Otherwise, if False, the reduced axes
(dimensions) must not be included in the result. Default: ``False``.
dtype
data type of the returned array. If None,
if the default data type corresponding to the data type “kind” (integer or
floating-point) of x has a smaller range of values than the data type of x
(e.g., x has data type int64 and the default data type is int32, or x has data
type uint64 and the default data type is int64), the returned array must have
the same data type as x. if x has a floating-point data type, the returned array
must have the default floating-point data type. if x has a signed integer data
type (e.g., int16), the returned array must have the default integer data type.
if x has an unsigned integer data type (e.g., uint16), the returned array must
have an unsigned integer data type having the same number of bits as the default
integer data type (e.g., if the default integer data type is int32, the returned
array must have a uint32 data type). If the data type (either specified or
resolved) differs from the data type of x, the input array should be cast to the
specified data type before computing the product. Default: ``None``.
out
optional output array, for writing the result to.
Returns
-------
ret
array, if the product was computed over the entire array, a zero-dimensional
array containing the product; otherwise, a non-zero-dimensional array containing
the products. The returned array must have a data type as described by the dtype
parameter above.
>>> x = ivy.array([1, 2, 3])
>>> z = ivy.prod(x)
>>> print(z)
ivy.array(6)
>>> x = ivy.array([1, 0, 3])
>>> z = ivy.prod(x)
>>> print(z)
ivy.array(0)
"""
return current_backend(x).prod(
x, axis=axis, dtype=dtype, keepdims=keepdims, out=out
)
Implicitly, Ivy sets numpy as the default backend or operates with the backend corresponding to the specified data inputs until the user explicitly sets a different backend. The examples can be seen below:
# implicit
import ivy
x = ivy.array([1, 2, 3])
(type(ivy.to_native(x)))
# -> <class 'numpy.ndarray'>
import torch
t = torch.tensor([23,42, -1])
type(ivy.to_native(ivy.sum(t)))
# -> <class 'torch.Tensor'>
|
# explicit
import ivy
ivy.set_backend("jax")
z = ivy.array([1, 2, 3]))
type(ivy.to_native(z))
# -> <class 'jaxlib.xla_extension.DeviceArray'>
|
This implicit backend selection, and the use of a shared global ivy namespace for all backends, are both made possible via the backend handler.
Frontend Functional APIs ✅#
While the backend API, Ivy API, and backend handler enable all Ivy code to be framework-agnostic, they do not, for example, enable PyTorch code to be framework agnostic. But with frontend APIs, we can also achieve this!
Let’s take a look at how the implementation of clip method would seem like in the frontends:
# ivy/functional/frontends/jax/lax/functions.py
def clamp(x_min,x, x_max):
return ivy.clip(x, x_min, x_max)
# ivy/functional/frontends/numpy/general.py
def clip(x, x_min, x_max):
return ivy.clip(x, x_min, x_max)
# ivy/functional/frontends/tensorflow/general.py
def clip_by_value(x, x_min, x_max):
return ivy.clip(x, x_min, x_max)
# ivy/functional/frontends/torch/general.py
def clamp(x, x_min, x_max):
return ivy.clip(x, x_min, x_max)
combined, we have the following situation:
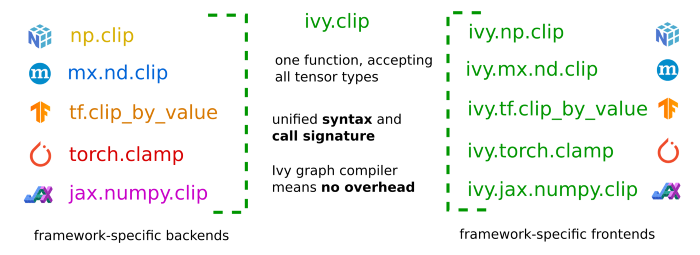
Importantly, we can select the backend and frontend independently from one another. For example, this means we can select a JAX backend, but also select the PyTorch frontend and write Ivy code which fully adheres to the PyTorch functional API. In the reverse direction: we can take pre-written pure PyTorch code, replace each PyTorch function with the equivalent function using Ivy’s PyTorch frontend, and then run this PyTorch code using JAX:
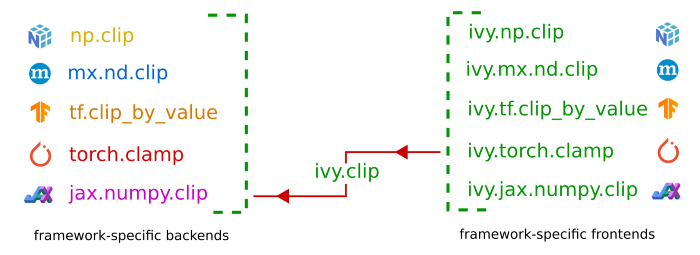
For this example it’s very simple, the differences are only syntactic, but the above process works for any function. If there are semantic differences then these will be captured (a) in the wrapped frontend code which expresses the frontend method as a composition of Ivy functions, and (b) in the wrapped backend code which expressed the Ivy functions as compositions of backend methods.
Let’s take a more complex example and convert the PyTorch method torch.nn.functional.one_hot() into NumPy code.
The frontend is implemented by wrapping a single Ivy method ivy.one_hot() as follows:
# ivy/functional/frontends/torch/nn/sparse_functions.py
def one_hot(tensor, num_classes=-1):
return ivy.one_hot(tensor, num_classes)
Let’s look at the NumPy backend code for this Ivy method:
# ivy/functional/backends/numpy/general.py
def one_hot(
indices: np.ndarray, depth: int, *, device: str, out: Optional[np.ndarray] = None
) -> np.ndarray:
res = np.eye(depth)[np.array(indices).reshape(-1)]
return res.reshape(list(indices.shape) + [depth])
By chaining these methods together, we can now call torch.nn.functional.one_hot() using NumPy:
import ivy
import ivy.frontends.torch as torch
ivy.set_backend('numpy')
x = np.array([0., 1., 2.])
ret = torch.nn.functional.one_hot(x, 3)
Let’s take one more example and convert TensorFlow method tf.cumprod() into PyTorch code.
This time, the frontend is implemented by wrapping two Ivy methods ivy.cumprod(), and ivy.flip() as follows:
# ivy/functional/frontends/tensorflow/math.py
def cumprod(x, axis=0, exclusive=False, reverse=False, name=None):
ret = ivy.cumprod(x, axis, exclusive)
if reverse:
return ivy.flip(ret, axis)
return ret
Let’s look at the PyTorch backend code for both of these Ivy methods:
# ivy/functional/backends/torch/general.py
def cumprod(
x: torch.Tensor,
axis: int = 0,
exclusive: bool = False,
*,
out: Optional[torch.Tensor] = None,
) -> torch.Tensor:
if exclusive:
x = torch.transpose(x, axis, -1)
x = torch.cat((torch.ones_like(x[..., -1:]), x[..., :-1]), -1, out=out)
res = torch.cumprod(x, -1, out=out)
return torch.transpose(res, axis, -1)
return torch.cumprod(x, axis, out=out)
# ivy/functional/backends/torch/manipulation.py
def flip(
x: torch.Tensor,
axis: Optional[Union[int, Sequence[int]]] = None,
*,
out: Optional[torch.Tensor] = None,
) -> torch.Tensor:
num_dims: int = len(x.shape)
if not num_dims:
return x
if axis is None:
new_axis: List[int] = list(range(num_dims))
else:
new_axis: List[int] = axis
if isinstance(new_axis, int):
new_axis = [new_axis]
else:
new_axis = new_axis
new_axis = [item + num_dims if item < 0 else item for item in new_axis]
ret = torch.flip(x, new_axis)
return ret
Again, by chaining these methods together, we can now call tf.math.cumprod() using PyTorch:
import ivy
import ivy.frontends.tensorflow as tf
ivy.set_backend('torch')
x = torch.tensor([[0., 1., 2.]])
ret = tf.math.cumprod(x, -1)
Backend Handler ✅#
All code for setting and unsetting the backend resides in the submodule at ivy/utils/backend/handler.py, and the front facing function is ivy.current_backend().
The contents of this function are as follows:
# ivy/utils/backend/handler.py
def current_backend(*args, **kwargs):
global implicit_backend
# if a global backend has been set with set_backend then this will be returned
if backend_stack:
f = backend_stack[-1]
if verbosity.level > 0:
verbosity.cprint(f"Using backend from stack: {f}")
return f
# if no global backend exists, we try to infer the backend from the arguments
f = _determine_backend_from_args(list(args) + list(kwargs.values()))
if f is not None:
if verbosity.level > 0:
verbosity.cprint(f"Using backend from type: {f}")
implicit_backend = f.current_backend_str()
return f
return importlib.import_module(_backend_dict[implicit_backend])
If a global backend framework has been previously set using for example ivy.set_backend('tensorflow'), then this globally set backend is returned.
Otherwise, the input arguments are type-checked to infer the backend, and this is returned from the function as a callable module with all bound functions adhering to the specific backend.
The functions in this returned module are populated by iterating through the global ivy.__dict__ (or a non-global copy of ivy.__dict__ if non-globally-set), and overwriting every function which is also directly implemented in the backend-specific namespace.
The following is a slightly simplified version of this code for illustration, which updates the global ivy.__dict__ directly:
# ivy/utils/backend/handler.py
def set_backend(backend: str):
# un-modified ivy.__dict__
global ivy_original_dict
if not backend_stack:
ivy_original_dict = ivy.__dict__.copy()
# add the input backend to the global stack
backend_stack.append(backend)
# iterate through original ivy.__dict__
for k, v in ivy_original_dict.items():
# if method doesn't exist in the backend
if k not in backend.__dict__:
# add the original ivy method to backend
backend.__dict__[k] = v
# update global ivy.__dict__ with this method
ivy.__dict__[k] = backend.__dict__[k]
# maybe log to the terminal
if verbosity.level > 0:
verbosity.cprint(
f'Backend stack: {backend_stack}'
)
The functions implemented by the backend-specific backend such as ivy.functional.backends.torch only constitute a subset of the full Ivy API.
This is because many higher level functions are written as a composition of lower level Ivy functions.
These functions therefore do not need to be written independently for each backend framework.
A good example is ivy.lstm_update(), as shown:
# ivy/functional/ivy/layers.py
@to_native_arrays_and_back
@handle_nestable
def lstm_update(
x: Union[ivy.Array, ivy.NativeArray],
init_h: Union[ivy.Array, ivy.NativeArray],
init_c: Union[ivy.Array, ivy.NativeArray],
kernel: Union[ivy.Array, ivy.NativeArray],
recurrent_kernel: Union[ivy.Array, ivy.NativeArray],
bias: Optional[Union[ivy.Array, ivy.NativeArray]] = None,
recurrent_bias: Optional[Union[ivy.Array, ivy.NativeArray]] = None,
) -> Tuple[ivy.Array, ivy.Array]:
"""Perform long-short term memory update by unrolling time dimension of the input array.
Parameters
----------
x
input tensor of LSTM layer *[batch_shape, t, in]*.
init_h
initial state tensor for the cell output *[batch_shape, out]*.
init_c
initial state tensor for the cell hidden state *[batch_shape, out]*.
kernel
weights for cell kernel *[in, 4 x out]*.
recurrent_kernel
weights for cell recurrent kernel *[out, 4 x out]*.
bias
bias for cell kernel *[4 x out]*. (Default value = None)
recurrent_bias
bias for cell recurrent kernel *[4 x out]*. (Default value = None)
Returns
-------
ret
hidden state for all timesteps *[batch_shape,t,out]* and cell state for last
timestep *[batch_shape,out]*
"""
# get shapes
x_shape = list(x.shape)
batch_shape = x_shape[:-2]
timesteps = x_shape[-2]
input_channels = x_shape[-1]
x_flat = ivy.reshape(x, (-1, input_channels))
# input kernel
Wi = kernel
Wi_x = ivy.reshape(
ivy.matmul(x_flat, Wi) + (bias if bias is not None else 0),
batch_shape + [timesteps, -1],
)
Wii_x, Wif_x, Wig_x, Wio_x = ivy.split(Wi_x, 4, -1)
# recurrent kernel
Wh = recurrent_kernel
# lstm states
ht = init_h
ct = init_c
# lstm outputs
hts_list = []
# unrolled time dimension with lstm steps
for Wii_xt, Wif_xt, Wig_xt, Wio_xt in zip(
ivy.unstack(Wii_x, axis=-2),
ivy.unstack(Wif_x, axis=-2),
ivy.unstack(Wig_x, axis=-2),
ivy.unstack(Wio_x, axis=-2),
):
htm1 = ht
ctm1 = ct
Wh_htm1 = ivy.matmul(htm1, Wh) + (
recurrent_bias if recurrent_bias is not None else 0
)
Whi_htm1, Whf_htm1, Whg_htm1, Who_htm1 = ivy.split(
Wh_htm1, num_or_size_splits=4, axis=-1
)
it = ivy.sigmoid(Wii_xt + Whi_htm1)
ft = ivy.sigmoid(Wif_xt + Whf_htm1)
gt = ivy.tanh(Wig_xt + Whg_htm1)
ot = ivy.sigmoid(Wio_xt + Who_htm1)
ct = ft * ctm1 + it * gt
ht = ot * ivy.tanh(ct)
hts_list.append(ivy.expand_dims(ht, -2))
return ivy.concat(hts_list, -2), ct
We could find and wrap the functional LSTM update methods for each backend framework which might bring a small performance improvement, but in this case there are no functional LSTM methods exposed in the official functional APIs of the backend frameworks, and therefore the functional LSTM code which does exist for the backends is much less stable and less reliable for wrapping into Ivy. Generally, we have made decisions so that Ivy is as stable and scalable as possible, minimizing dependencies to backend framework code where possible with minimal sacrifices in performance.
Source-to-Source Transpiler ✅#
Round Up
Hopefully, this has painted a clear picture of the fundamental building blocks underpinning the Ivy framework, being the Backend functional APIs, Ivy functional API, Backend handler, and Tracer 😄
Please reach out on discord if you have any questions!